每个网站所有者和营销商当然希望他们的网站在搜索引擎结果页(SERP)上排名更高。是不是
好吧,即使在您的内容在SERP上排名之前,对您而言在网站上建立层次结构也是至关重要的。
这可以使您为网站上最重要的帖子和页面提供比不那么有价值的链接更多的链接价值。
简而言之,制定有竞争力的内部链接策略实际上可以 促进您的SEO 工作。
但是在此之前,我们知道。。。您急于想知道内部链接是什么?
因此,让我们立即了解什么是内部链接。
内部链接不过是指向链接所在的同一域(或目标域)(即源)的超链接。简而言之,内部链接是指向同一网站上不同页面的链接。
Google通过在Google漫游器的帮助下遵循特定的链接(内部和外部)来跨网站爬网。
机器人首先到达网站的主页。然后,他们通过内部链接来确定不同帖子,页面和其他类型的Web内容之间的关系。
这样,Google最终可以确定您网站上的哪个页面具有用户正在搜索的相似主题。
以下是内部代码的格式:
<a href=”http://www.same-domain.com/”title=”关键字文字”>关键字文字</a>
内部链接的最佳形式将在锚点文本中包含描述性词,以提供源页面所针对的关键字或主题的含义。
内部链接是从一页到另一页的那些链接。但是,这两个页面将位于同一 域中。
这些链接主要用于主网站导航。
使用内部链接的原因有以下三个:
建立内部链接对于传播链接资产和建立良好的网站体系结构极为重要。
出于同样的原因,在本节中,我们将看到如何使用内部链接来构建SEO友好的网站体系结构。
搜索引擎必须在您网站的每个页面上看到内容。
只有这样,他们才能在其大量基于关键字的索引中列出您的网页。
此外,他们应该可以轻松访问可以爬网的链接网站结构。
这种结构允许蜘蛛浏览站点的路径。
该结构使蜘蛛程序可以窥视网站的链接结构。
一些网站犯了这样的错误:不恰当地隐藏其链接导航,以致搜索引擎无法访问它。
这样的设置使他们很难在搜索引擎的索引中列出。
下图描述了这种问题可能如何发生。
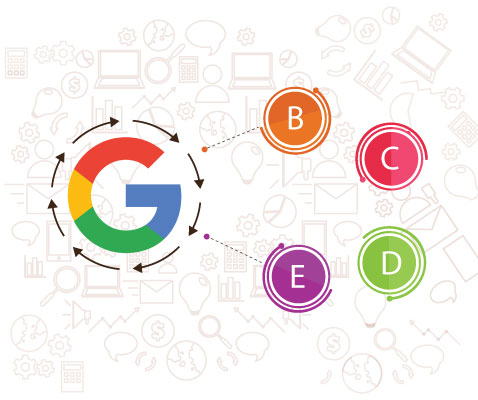
在上面的示例中,谷歌的彩色蜘蛛已经落在页面“ A”上。然后,它找到到页面“ E”和“ B”的内部链接。无论页面“ D”和“ C”对网站有多重要,Google的蜘蛛都不知道如何找到它。
更糟糕的是,它甚至不知道这些页面确实存在。这是因为没有指向这两个页面的直接可爬网链接。
因此,根据Google所说,这两个页面不存在。
如果Google蜘蛛无法访问这些网页,那么即使是良好的关键字定位,明智的营销和出色的内容也不会有所作为。
在这里,顶部的大页面不过是首页。
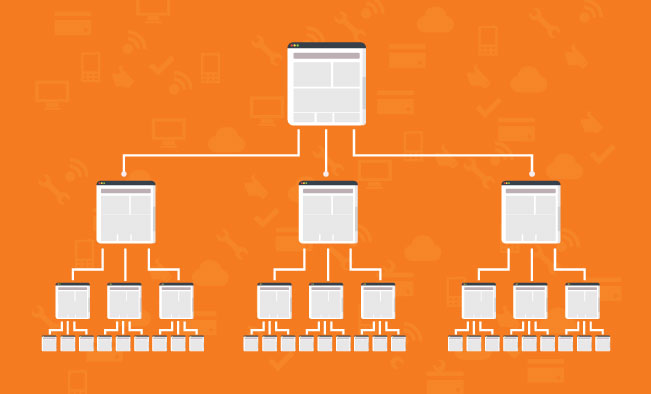
在这里,您应该注意,首页具有指向任何给定网页的最少链接。
这很棒,因为它使链接资产或排名能力可以无缝地流遍整个网站。
这增加了每个页面的排名潜力。而且,这是大多数高性能网站之后的通用网站结构,其中之一就是amazon.com。
此类站点具有适当的多个类别和子类别系统。
但是,这是如何实现的。解决该问题的一种好方法是使用补充URL结构和内部链接。
例如,它们使用锚文本“猫”在内部链接到http://www.example.com/mammals。
以下是内部链接的正确格式:
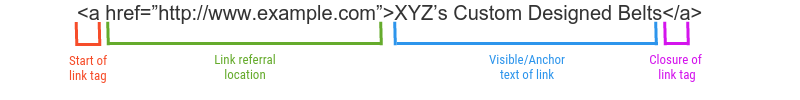
在上图中,标签“ a”代表链接的开始。
这些链接标签可以具有文本,图像和各种其他元素,这些元素在网页上提供“可单击”区域,可帮助用户参与并导航到其他页面。
这是互联网的实际概念。链接引用位置可将内部链接指向的搜索引擎和浏览器引导。
使链接结构保持基本状态可以使搜索引擎突出了解它。
然后,搜索引擎蜘蛛将将此链接添加到其链接图中,利用它来分析与查询无关的变量,并按照该链接为所引用的Web内容建立索引。
经常困扰营销人员的另一个问题是“内部链接是否应在新标签页中打开”?
好吧,当然可以。但是,我们认为这完全取决于您的偏好。但是,如果您选择在新标签页中打开内部链接,则请确保已通知用户。
有时,您的网页可能无法访问。以下是一些导致页面无法访问从而阻止对这些页面建立索引的原因。
表单通常包含一些元素,这些元素要么简单如“下拉”菜单,要么复杂如冗长的调查。在任何一种情况下,搜索蜘蛛都不会尝试执行所请求的任务-即完成调查或提交表格。
因此,在完成特定任务后任何可用的内容将对搜索爬网程序完全不可见。
这是一个非常明显的原因,因为搜索引擎机器人肯定不会进行内部搜索。
一些网站所有者犯了一个错误,那就是将许多页面隐藏在完全无法访问的内部搜索框后面。
内置Javascript的链接会根据其实现而在权重上贬值,或者无法被爬网。
因此,一种防止这种情况的最佳方法是对搜索引擎引用的流量极为重要并限制使用Javascript的页面使用标准HTML链接。
嵌入Java小程序,Flash和其他各种插件中的链接通常对搜索引擎不可用。
该 的robots.txt和meta robots标签 使营销和网站所有者限制成为访问搜索引擎蜘蛛的页面。
这可能会对您的内部链接SEO工作产生负面影响。
大致来说,搜索引擎机器人的抓取限制是每页150个链接。一旦达到此限制,他们就会停止搜寻从原始页面链接回的多余页面。
但是,此限制是灵活的,一些重要的网页最多可以具有200个或250个链接。通常,最好将任何给定网页上的链接总数限制为150个。
这样就消除了防止其他页面被爬网的风险。
基本上,可以检索存在于I框架和框架中的链接。
但是,当涉及到组织和关注时,两者都给搜索爬虫带来一些结构上的复杂性。
因此,建议您充分了解搜索引擎如何跟踪框架中的链接,并在将它们与内部链接一起使用时对其进行索引。
通过避免这些错误,您可以获得HTML链接,这使搜索引擎蜘蛛可以轻松快速地访问内容页面。
您可以在链接中添加几个其他属性,但是搜索搜寻器完全忽略所有这些属性。
您可以使用诸如Screaming Frog, Moz Pro 和 Open Site Explorer之类的工具进行网站爬 网。
稍后,您可以通过运行site:search将已爬网的页面数与列出的页面进行比较。
另一方面,网站内部链接检查器使您可以识别搜索引擎蜘蛛可以检测到的链接。
此外,每个搜索引擎通常以稍微不同的方式中断内部链接nofollow或nofollow内部链接。
接下来,SEO友好的内部链接为您提供了建立内部链接的宝贵机会。这是帮助您的网站排名更高的重要因素。
此外,SEO中明智的内部链接构建还可以帮助搜索用户查询,并帮助他们轻松浏览您的网站。







