Robots.txt文件用于向扫描网络的搜索系统提供有价值的数据。在检查您网站的页面之前,搜索机器人会对此文件进行验证。由于这种过程,它们可以提高扫描效率。这样,您可以帮助搜索系统首先对站点上最重要的数据进行索引。但这只有在您正确配置了robots.txt之后才有可能。
就像robots.txt文件的指令一样,元标记robots中的noindex指令不仅仅只是针对机器人的建议。这就是为什么他们不能保证关闭的页面不会被索引并且不会包含在索引中的原因。在这方面的保证是不合适的。如果您需要关闭站点的某些部分以建立索引,则可以使用密码来关闭目录。
如果您的网站没有机械手txt文件,则将完全爬网您的网站。这意味着所有网站页面都将进入搜索索引,这可能会对SEO造成严重问题。
用户代理:将要应用以下规则的机器人(例如“ Googlebot ”)。用户代理字符串是Web浏览器用作其名称的参数。但是它不仅包含浏览器的名称,还包含操作系统的版本和其他参数。由于用户代理的原因,您可以确定很多参数:操作系统名称,版本;检查安装了浏览器的设备;定义浏览器的功能。
禁止:您要关闭以访问的页面(在每行开始时,您都可以包括类似的大量指令)。每组User-Agent / Disallow均应以空白行分隔。但是,非空字符串不应在组内出现(在User-Agent和最后一个指令Disallow之间)。
当需要在当前行的robots.txt文件中保留注释时,可以使用井号(#)。井号后面提到的所有内容都将被忽略。该注释既适用于整行,也适用于指令之后的结尾。目录和文件名对寄存器有意义:搜索系统接受《目录》,《目录》和《目录》作为不同的指令。
主机:用于Yandex指出主要镜像站点。这就是为什么如果您每页执行301重定向以将两个站点粘贴在一起,则无需重复执行文件robots.txt(在重复站点上)的过程。因此,Yandex将在需要被卡住的站点上检测到上述指令。
抓取延迟:您可以限制站点遍历的速度,这在站点上的出勤频率很高的情况下非常有用。之所以启用该选项,是为了避免由于处理站点信息的搜索系统多样化而导致服务器额外负载出现问题。
正则表达式:为了提供更灵活的指令设置,可以使用下面提到的两个符号:
*(星号)–表示任何符号序列,
$(美元符号)–代表行尾。
User-agent: *
Disallow: /创建新站点并使用子域提供对它的访问权限时,需要应用此说明。
通常,在新站点上工作时,Web开发人员会忘记关闭站点的某些部分以进行索引编制,结果,索引系统会处理该站点的完整副本。如果发生此类错误,则您的主域需要每页进行301重定向。
User-agent: *
Disallow:User-agent: Googlebot
Disallow: /no-index/User-agent: Googlebot
Disallow: /no-index/this-page.htmlUser-agent: *
Disallow: /*.pdf$User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.htmlUser-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml如果您不断用独特的内容填充网站,则在使用此指令时要考虑的特殊性:
许多不公平的网站管理员会解析其他网站的内容,但这些网站都是他们自己的,并将其用于自己的项目。
检查您的网站页面的索引状态
检测所有未索引的URL,并找出搜索引擎机器人可以检索哪些网站页面
如果您不希望某些页面进行索引编制,则元标记机器人中的noindex更为可取。要实现它,您需要在页面的部分中添加以下元标记:
<meta name="robots" content="noindex, follow">使用这种方法,您将:
Robots.txt最好关闭以下类型的页面:
生成robots.txt文件时,需要验证它们是否包含任何错误。有一些工具可以帮助您完成此任务。
现在,只有旧版本的Google Search Console可以测试机器人文件。使用在其平台上确认的当前站点登录帐户,然后使用此路径查找验证器。
旧版本的Google搜索控制台>抓取> Robots.txt测试器
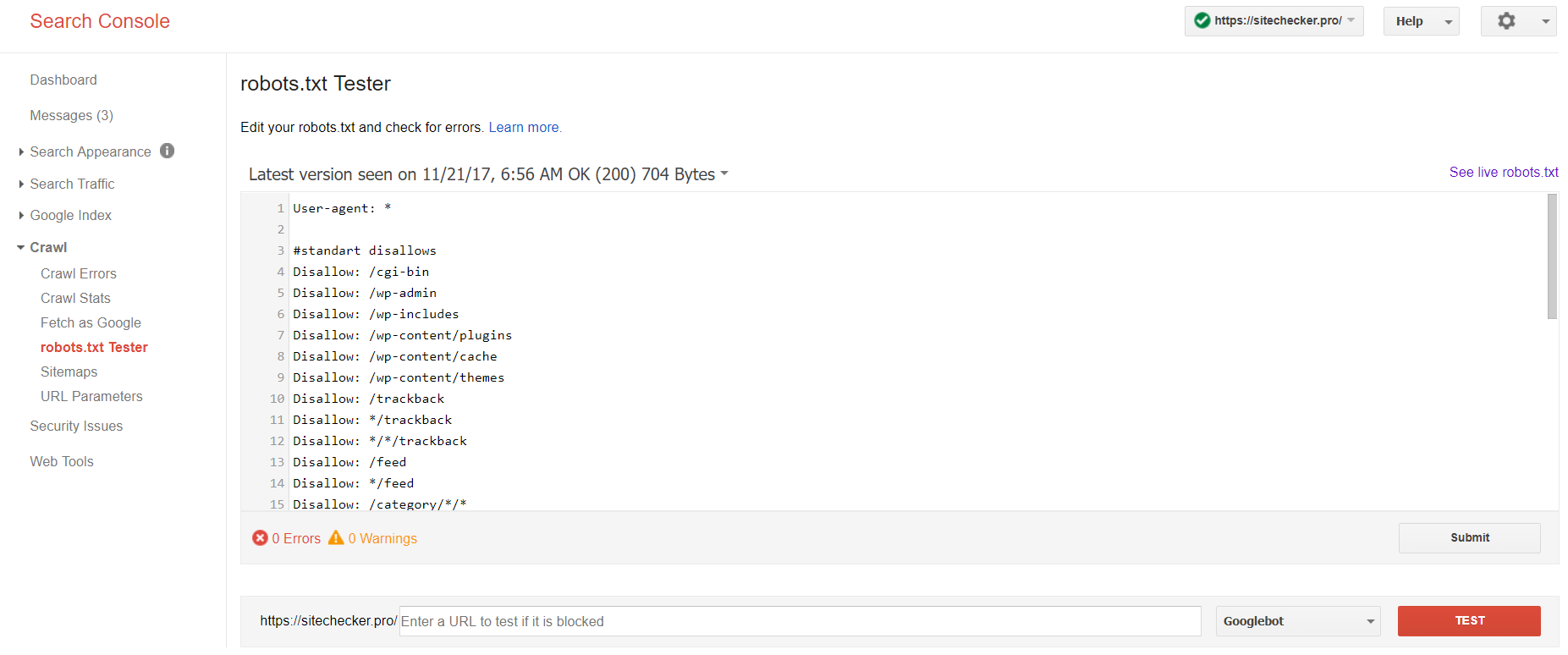
通过robot.txt测试,您可以:
在平台上确认了当前站点的情况下登录Yandex Webmaster帐户,然后使用此路径查找该工具。
Yandex网站管理员>工具> Robots.txt分析
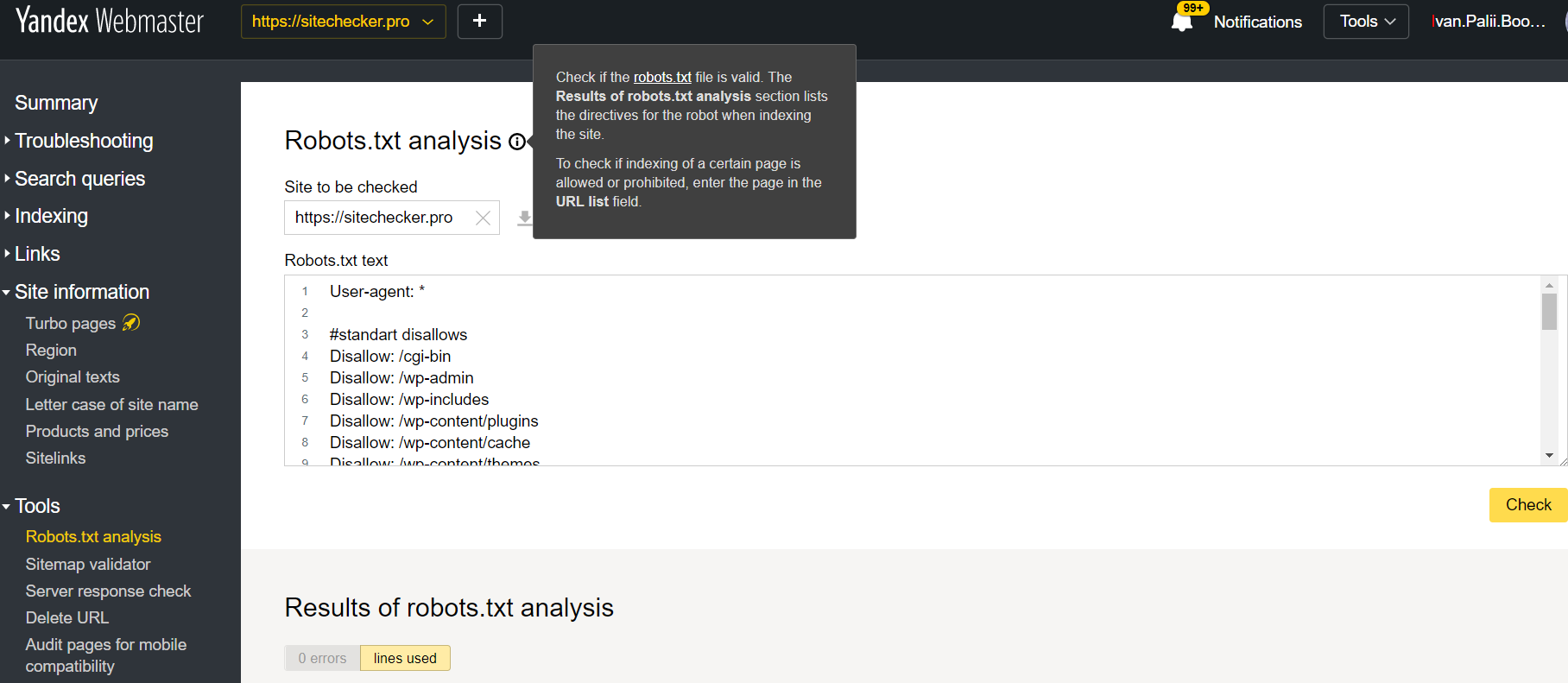
该测试仪提供与上述几乎相同的验证机会。区别在于:
这是批量检查的解决方案。我们的抓取工具可帮助审核整个网站,并检测robots.txt中不允许使用的URL,以及通过noindex meta标签将其中哪些URL禁止索引。
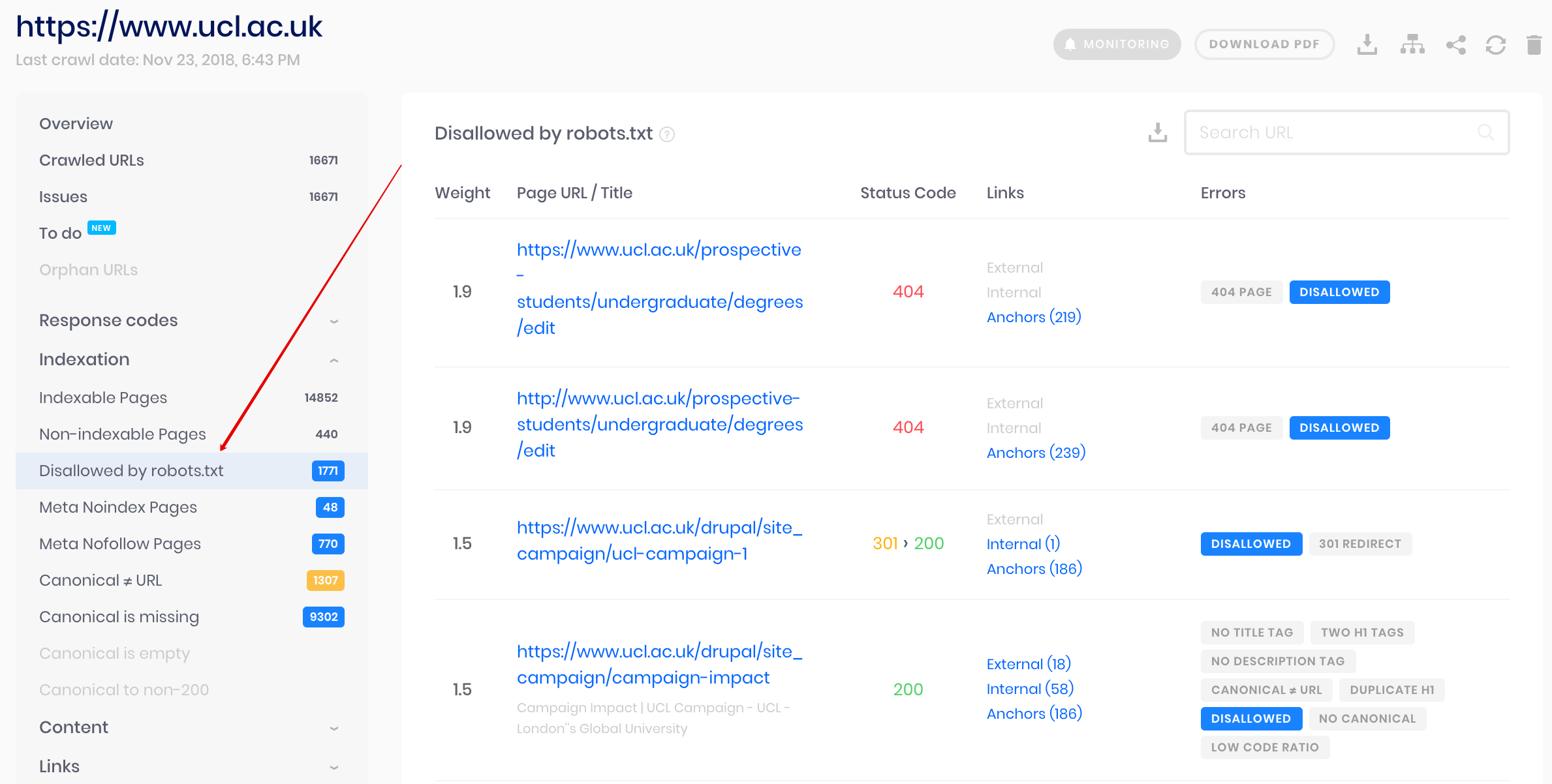
请注意:要检测不允许的网页,您应该使用“ ignore robots.txt”设置来抓取网站。
首先,这完全是关于预算的抓取。每个站点都有自己的抓取预算,这些预算由搜索引擎亲自估算。Robots.txt文件可防止搜索引擎抓取您的网站不必要的页面,例如 重复页面,垃圾页面和非高质量页面。主要的问题是搜索引擎的索引得到了不应有的内容-页面不会给人们带来任何好处,只会给搜索带来麻烦。
但是它如何危害SEO?答案很简单。当搜索机器人进入网站进行爬网时,它们没有被编程为浏览最重要的页面。通常,他们会扫描整个网站及其所有页面。因此,由于抓取预算有限,最重要的页面无法被扫描。因此,Google或任何其他搜索引擎会根据您收到的信息开始对您的网站进行搜索。这样,由于页面不相关,您的SEO策略很有可能失败。







