我们遇到了几个仍然对XML站点地图有误解的客户。
SEO,作为最强大的网站推广方法,很小的错误就可能使您落后于竞争对手。
无论是关键字,元描述,标题标签,Robots.txt,站点地图还是Alt标签,在添加到页面之前,都必须注意其功能和优化。
当然,它们功能强大,这就需要更好地了解XML网站地图的工作方式。
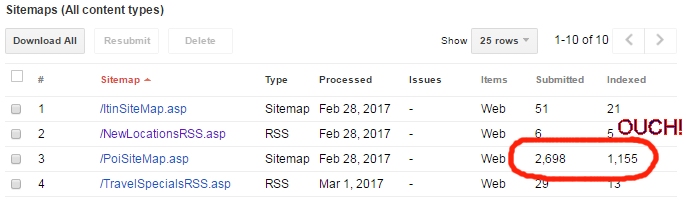
每天都会创建数百万个网站,其中有50%的网站由于索引而未被注意到。
网站很难被抓取,因此不会在搜索结果中被选中。
常见的误解是XML网站地图会为您的页面建立索引。
让我们提醒您,对您的页面进行索引不是因为您请求Google而是因为Google认为您的页面值得索引。
Google有特定的标准来爬网页面,如果您的页面令人满意,则一定会对您的网站建立索引。
话虽如此,您必须向Google表示您的网页需要抓取。
您可以通过将XML网站地图提交到Google Search Console来实现。
它还向Google发出信号,指出这些页面很重要,必须对其进行爬网。
个人所做的最普遍的误解中的一个突出之处是缺乏一致性来告知Google有关页面的信息。
网站是一个持续的过程,而更改是其中的一部分。您可能已在网站上添加了几页,内容可能已完成一半。
您绝对不希望Google对其进行爬网。因此,“ noindex,follow”将被添加到页面。
如果您在robots.txt中屏蔽了某个页面,但仍将其合并到XML网站地图中,那么您真的很傻。
同样不要出错,将页面包含在XML网站地图中,然后将元漫游器设置为“ noindex,follow”。
Google有 严格的准则 来检查网站的质量。
假设您有100个页面添加到您的网站,但是所有这些都相关吗?
绝对不!
可能只有5-6个页面可以提供全面的信息,并且可以满足Google的所有条件。
您肯定希望只将最相关的页面呈现给用户。
每个站点都有特定数量的“实用程序”页面,这些页面对客户来说很有价值,但是并不是真正应该从设计中获得的内容类型页面:用于向他人传授实质内容,回答评论,登录以及找回丢失内容的页面Google会给这个秘密词一个权重。
如果您的XML网站地图包含登录页面,登录详细信息,找回丢失的密码,回复评论,那么您有什么机会传达给Google?
您几乎不知道什么构成网站上的重要内容,什么不构成网站!
假设您有一个包含400个页面的网站,但其中只有175个页面的内容很棒。
您可以忽略剩下的225页。
考虑到Google抓取了175个页面。Google会审核这些页面,如果100页属于A级,B级为50页,B +为25页,则您的网站很棒,可以与用户共享。
想象一下,您已经提交了所有400个要通过XML网站地图建立索引的页面。
Google审查了全部400页,发现超过250页属于F级。
其余100页为D级,最后50页为E级。
总体而言,这表明您的网站很烂,并且Google肯定不想与用户共享这样的网站。
Google会认为您在XML网站地图中提交的所有页面都非常重要。
无论如何,由于它不在您的XML网站地图中,因此并不表示Google会忽略这些页面。
您可能有成千上万个内容较少的页面,但它们仍可能被索引。
进行站点搜索并找出您忘记提交的页面至关重要。
另外,您必须检查平均评分页面并进行必要的更改以 升级级别。
使用元漫游器和使用robots.txt来抵消页面索引之间存在必然的但不明显的区别。
使用 元机器人“ noindex,follow” 可以使前往该页面的链接资产流到其连接的页面。
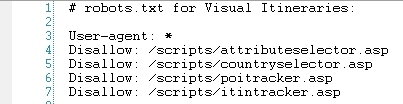
如果您用robots.txt挡住了页面的机会,您只需将其冲洗到垃圾箱中即可。

您什么时候要使用robots.txt?
也许当您遇到抓取带宽问题时,或者当Googlebot投入大量精力获取实用程序页面时,只是为了在其中找到元机器人“ noindex,follow”并提供帮助。
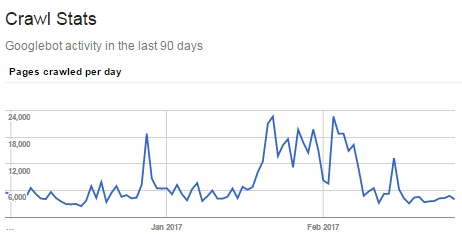
如果您有大量这样的页面,而Googlebot无法访问您的重要页面,那您可能会不得不使用robots.txt阻止它们。
您可能会想,您必须使用元机器人将XML站点地图手动同步到站点上所有页面的数十万个页面。
好吧,这有点困难。
但是,没有令人信服的理由手动执行此操作。XML站点地图不必是静态记录。
说实话,他们不需要.XML扩展即可在Google Search Console中提交它们 。
您可以在页面本身中设置meta robots索引或noindex。







